October 5, 2015
by Dmitri Zimine, Patrick Hoolboom
A host is running out of disk space. What follows is a routine pager panic and rush in cleaning things up, at best. At worst, downtime. It is silly, but it happens much more than most of us care to admit.
This, and many other annoying events like this can, and shall be auto-remediated. The “classic” pattern of wiring monitoring to and paging is simply not good enough, and know it when you’re paged at 3am to clean the disk on production server.
And to those of you who hard-wire their remediation scripts into Nagios/Sensu event handlers, Splunk alert scripts and NewRelic web hooks: it is plain wrong there’s a better way.
In this blog, we show how StackStorm auto-remediation platform helps you hand out-of-disk case, with step-by-step walk-through and a working automation sample to kick-start your auto-remediation.
October 2, 2015
by Evan Powell
Let’s get right to it.
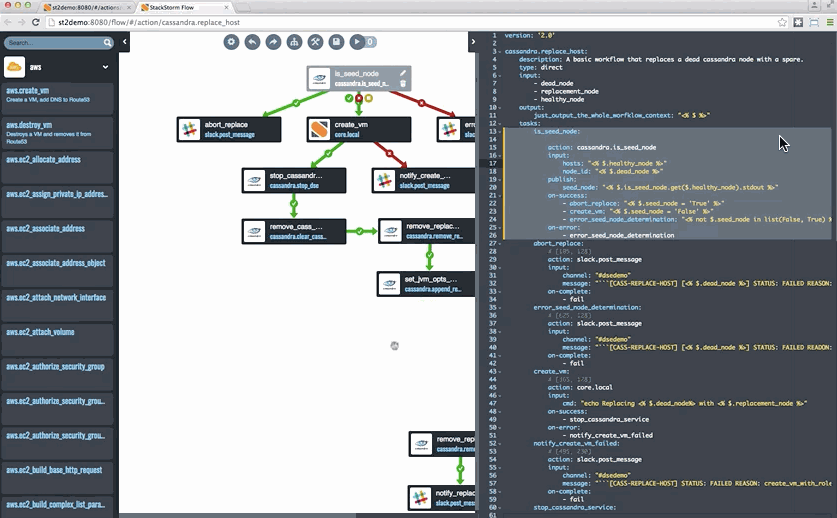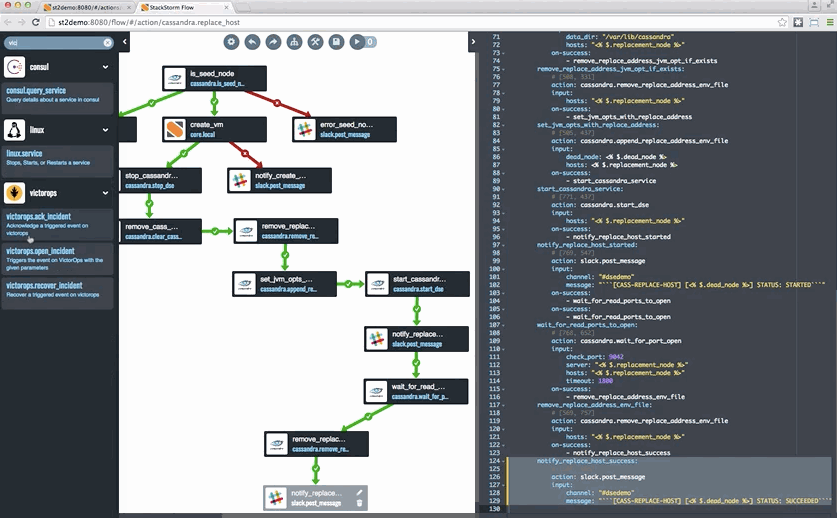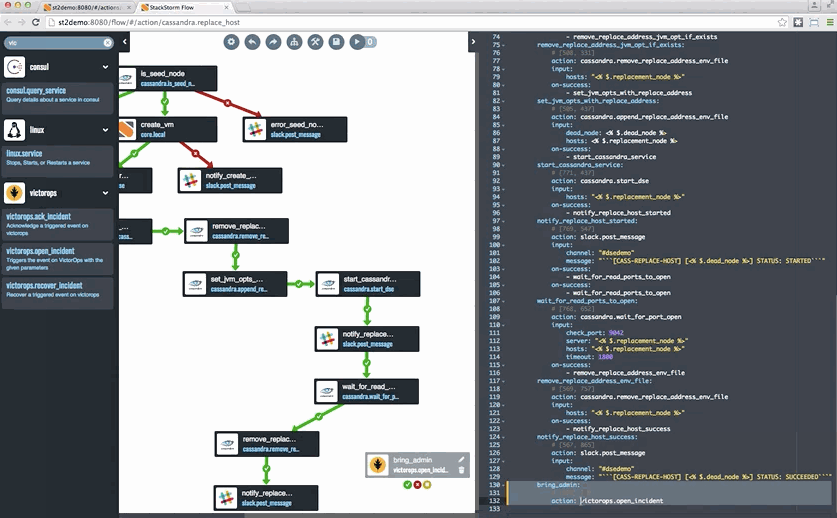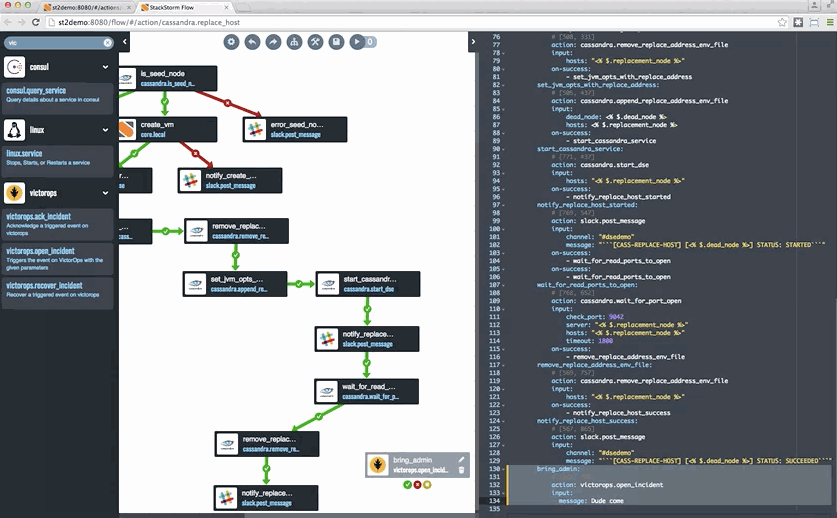
This week we feature a tutorial that published last week. It has to do with auto-remediating your environment. The tutorial focuses on using StackStorm to auto-remediation Cassandra; it was published at the Cassandra Summit after all – building on Netflix’s use of StackStorm for that use case.
October 1, 2015
Guest post by Anthony Shaw, Head of Innovation, ITaaS at Dimension Data
This blog post will take you through the integration pack for OctopusDeploy and give you some example actions and rules to integrate with other packs.
Octopus Deploy is an automated deployment tool for .NET and Windows environments. It has gained significant popularity amongst the .NET development community for it’s ease of use and integration into the Microsoft development ecosystem. OctopusDeploy enables users to automate deployment of applications, packages and tools to Windows environments.
Octopus Deploy provides a rich system for Windows application deployments, but this is typically part of a wider DevOps process. Unlike StackStorm, it does not support closed-loop monitoring, remediation or infrastructure configuration and building, it does not integrate into configuration management tools (nor claim to). If you want to integrate OctopusDeploy from another tool, as part of a DevOps or environment tool you could READ MORE…
September 23, 2015
by Evan Powell
Today we announce StackStorm 1.0 – and release our Enterprise Edition 1.0 release candidate.
Maybe more noteworthy, Netflix is announcing – at the Cassandra Summit which they are helping to keynote as one of the world’s largest Cassandra users – that they use StackStorm to auto-remediate their Cassandra environments.

It has been more than two years since we got StackStorm going. And last November – we open-sourced StackStorm.
READ MORE…
September 23, 2015
by Lakshmi Kannan
If “SLAs”, “five 9 uptime”, “pager fatigue” and “customer support” are phrases you use everyday in your work, you know by now auto-remediation is a serious use case. If you are running critical infrastructure of any kind, you may already be looking into auto-remediation, or even using it like Facebook, LinkedIn, Netflix (more on that later). The idea is that if you are running critical systems of any kind, you need to see when events happen and to act on them as fast as humanly possible. Actually, no, to improve mean time to recovery you need to respond FASTER than humanly possible.
September, 11 2015
by Dmitri Zimine
A StackStorm user with large investment in Java asked us: “Can I turn my Java code into StackStorm actions, and how?”
The answer is “Yes you can, in three basic steps”:

dotted.notation in workflows.August 26, 2015
by Lakshmi Kannan
We are excited to announce another release of StackStorm. 0.13 comes with some great features, user contributions and many bug fixes. It’s definitely worth upgrading and the upgrade should be non-eventful. If you are trying us out for the first time, use the shiny GUI installer!
You can bring your own box or use AWS AMI or a VMware VMDK or vagrant as the base box and kick off the (beta) installer after provisioning.
Please ask for support if you face issues!
Speaking of which, if you need help, a great place to get it is our slack community. If you haven’t registered yet, sign up here.
If you are entering into production with StackStorm, we do have support and professional service options that most of our known production users are leveraging. Sorry for the sales pitch, read more here: /services/
August 14, 2015
by Joe Topjian
For the past nine months or so, some of us at Cybera have been using a system called StackStorm. StackStorm is a very powerful tool that provides a hub for building automated workflows. That’s a pretty vague description, but StackStorm’s power comes from its amorphous character.
A core feature of StackStorm is the ability to store a library of “commands”. These commands can be anything: creating a ticket in Jira, executing an action on a remote server, doing a Google search — anything. We already had our own library of everyday commands, so our first task was to port this library into StackStorm. This process felt awkward. It quickly became obvious that most of our commands were focused on single-phase information reconnaissance. StackStorm seemed to work best with multi-phase workflows. The StackStorm team was very receptive to this feedback and worked with us on some simple changes that made our library a bit less awkward to use.
August 7, 2015
by Evan Powell
One thing I tried to do when helping kick off the “software defined storage” craze some years ago was to define what we meant at Nexenta by that term. A number of analysts in the space were positive about our clarity as were, more importantly, many users and partners.
I realized that while we’ve blogged here and there about what we mean at StackStorm by auto-remediation, we have not directly posited a canonical definition of it. People seem to grok that auto-remediation is a subset of event-driven automation however it is nigh time for us to have a single spot for our take on the definition. With no further adieu, please read on and comment back here or via twitter.
Auto remediation is an approach to automation that responds to events with automations able to fix, or remediate, underlying conditions. Remediation means more that simply clearing an alert; for example, it can mean ascertaining the scope of a problem through automated validation and investigation, noting the diagnosis of a problem in a ticketing system and very often in a chat system as well as in a logging system, and then taking a series of steps where each step’s completion or failure can be a prerequisite for the next step.