August 7, 2015
by Evan Powell
One thing I tried to do when helping kick off the “software defined storage” craze some years ago was to define what we meant at Nexenta by that term. A number of analysts in the space were positive about our clarity as were, more importantly, many users and partners.
I realized that while we’ve blogged here and there about what we mean at StackStorm by auto-remediation, we have not directly posited a canonical definition of it. People seem to grok that auto-remediation is a subset of event-driven automation however it is nigh time for us to have a single spot for our take on the definition. With no further adieu, please read on and comment back here or via twitter.
Auto remediation is an approach to automation that responds to events with automations able to fix, or remediate, underlying conditions. Remediation means more that simply clearing an alert; for example, it can mean ascertaining the scope of a problem through automated validation and investigation, noting the diagnosis of a problem in a ticketing system and very often in a chat system as well as in a logging system, and then taking a series of steps where each step’s completion or failure can be a prerequisite for the next step.
Components needed by auto-remediation software include the ability to listen to events, some notion of a rules engine to respond appropriately to these events, and a workflow engine to transparently execute often long running automations comprised of multiple discrete tasks tied together with conditional logic. Additionally, as discussed below, the human factors of auto-remediation are crucial as we build and increasingly trust autonomous systems to run ever more complex environments.
Attempts at auto remediation should recognize the challenges and limitations of prior attempts at closed loop automation most of which were at the time called “run book automation” with leading solutions including Opalis, Tidal Software, RealOps and others, most of which were purchased by large system vendors. These limitations have included:
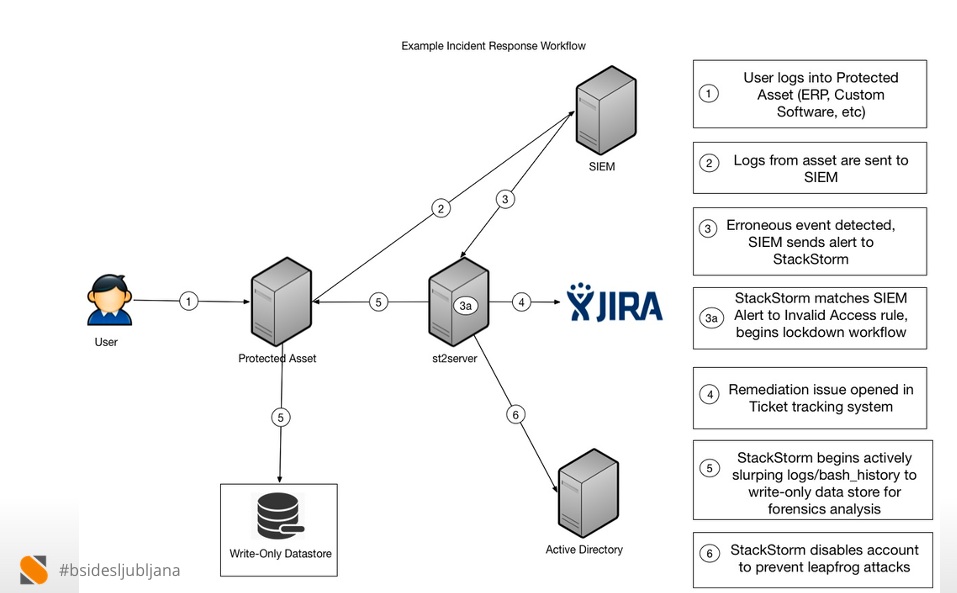
Successful auto remediation systems include Facebook’s Auto Remediation, or FBAR, and WebEx Spark’s Bootstrap 2.0. More information about these systems is available here for Facebook (although you would have learned more from the recent event driven automation meet-up) and here for WebEx’s Spark (disclosure, leverages StackStorm and from a later talk at the same meet-up).
You can read much more about example uses of event-driven automation and specifically auto-remediation on the StackStorm site. For here suffice it to say that use cases for auto-remediation range from providing resilient environments for your Cassandra cluster and other key components (more on that at the upcoming Cassandra Summit) to responding to a broad and ever changing set of cyber intrusions at banks and other larger targets. A good resource for the later use case including a demo is a talk given at BSides in the Spring by our own Tomaz Muraus.
Please help us solidify this definition. Any and all feedback is welcome.