October 5, 2015
by Dmitri Zimine, Patrick Hoolboom
A host is running out of disk space. What follows is a routine pager panic and rush in cleaning things up, at best. At worst, downtime. It is silly, but it happens much more than most of us care to admit.
This, and many other annoying events like this can, and shall be auto-remediated. The “classic” pattern of wiring monitoring to and paging is simply not good enough, and know it when you’re paged at 3am to clean the disk on production server.
And to those of you who hard-wire their remediation scripts into Nagios/Sensu event handlers, Splunk alert scripts and NewRelic web hooks: it is plain wrong there’s a better way.
In this blog, we show how StackStorm auto-remediation platform helps you hand out-of-disk case, with step-by-step walk-through and a working automation sample to kick-start your auto-remediation.
If you’re in the hurry, grab the automation code in st2_demos and run it on your StackStorm instance.
st2 pack install https://github.com/StackStorm/st2_demos
For the rest, let’s walk through the three steps of setting auto-remediation with StackStorm. First, configure the integrations with monitoring and paging system, Second, define your auto-remediation workflow, “runbook as code”. Third, create a rule mapping event to auto-remediation.
Install sensu and victorops pack from StackStorm Exchange:
st2 pack install sensu victorops
Configure to point to your Sensu and Victorops /opt/stackstorm/configs/sensu.yaml and /opt/stackstorm/configs/victorops.yaml.Or just run st2 pack config sensu and st2 pack config victorops, and answer the questions. Follow the detailed instructions on sensu pack to send Sensu events to StackStorm. If you are on Nagios, NewRelic, Splunk, or other monitoring – pick the integration for your tool. New integrations are easy to build, we welcome and support your contributions. Likewise, if you happen to use PagerDuty – grab and configure pagerduty pack.
In this example ChatOps with Slack is used to post updates and fire commands. If you’re on HipChat or IRC or some other chat, or still prefer Email or SMS or JIRA for notifications – adjust accordingly.
This is yours to define. Our example here is “if disk is filled up with log files, just prune them, if it’s something else, wake me up”. Read the workflow code from diskspace_remediation.yaml, it’s self-explanatory. Note that action results are passed down the flow.
---
version: '1.0'
input:
- hostname
- directory
- file_extension
- threshold
- event_id
- check_name
- alert_message
- raw_payload
tasks:
silence_check:
action: sensu.silence
input:
client: <% ctx().hostname %>
check: <% ctx().check_name %>
next:
- when: '{{ succeeded() }}'
do:
- check_dir_size
- when: '{{ failed() }}'
do:
- post_error_to_slack
check_dir_size:
action: st2_demos.check_dir_size
input:
hosts: <% ctx().hostname %>
directory: <% ctx().directory %>
threshold: <% ctx().threshold %>
next:
- when: '{{ succeeded() }}'
do:
- post_error_to_slack
- when: '{{ failed() }}'
do:
- remove_files
remove_files:
action: core.remote_sudo
input:
hosts: <% ctx().hostname %>
cmd: rm -Rfv <% ctx().directory %>/*<% ctx().file_extension %>
next:
- when: '{{ succeeded() }}'
do:
- validate_dir_size
- when: '{{ failed() }}'
do:
- post_error_to_slack
validate_dir_size:
action: st2_demos.check_dir_size
input:
hosts: <% ctx().hostname %>
directory: <% ctx().directory %>
threshold: <% ctx().threshold %>
next:
- when: '{{ succeeded() }}'
do:
- post_success_to_slack
- when: '{{ failed() }}'
do:
- post_error_to_slack
post_success_to_slack:
action: chatops.post_message
input:
channel: '#demos'
message: "DemoBot has pruned <% ctx().directory %> on <% ctx().hostname %> due to a monitoring event. ID: <% ctx().event_id %>\nhttps://st2demo004/#/history/<% ctx().st2.action_execution_id %>/general"
post_error_to_slack:
action: chatops.post_message
input:
channel: '#demos'
message: "Something has gone wrong with DemoBot - check https://st2demo004/#/history/<% ctx().st2.action_execution_id %>/general"
Define your workflow your way. Your environment, tools and run books are special. You may want to move files to s3 instead of deleting. Or provision and attach an extra volume. Or check for few other suspects before paging. And your logic will differ dependent on server role. Please yourself, mix and match your scripts with existing building blocks in the workflow that works for your case.
If you are on StackStorm Enterprise: the workflow graphical editor, Workflow Designer, will help create and visualize the workflows. Here is how the our sample diskspace remediation looks in Workflow Designer:
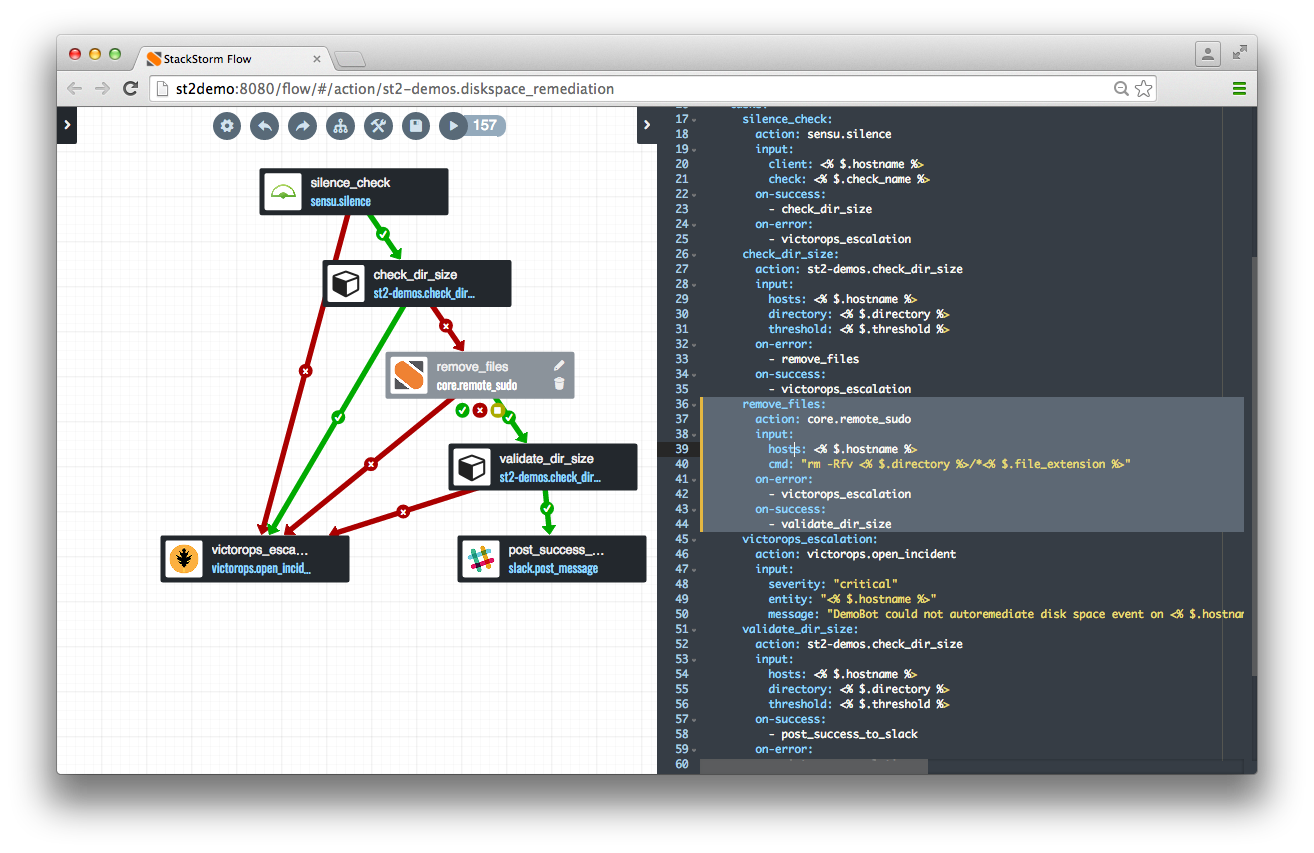
Create a rule: if monitoring event triggers, fire the remediation action. The rule definition code shown below. Note that the trigger payload is parsed, used in criteria, and passed in action input.
---
# rules/diskspace_remediation.yaml
name: "diskspace_remediation"
pack: "st2_demos"
description: "Clean up disk space on critical monitoring event."
enabled: true
trigger:
type: "sensu.event_handler"
criteria:
trigger.check.status:
pattern: 2
type: "equals"
trigger.check.name:
pattern: "demo_diskspace"
type: "equals"
action:
ref: "st2_demos.diskspace_remediation"
parameters:
hostname: "{{trigger.client.name}}"
directory: "{{system.logs_dir}}"
threshold: "{{system.logs_dir_threshold}}"
event_id: "{{trigger.id}}"
check_name: "{{trigger.check.name}}"
alert_message: "{{trigger.check.output}}"
raw_payload: "{{trigger}}"
If you like StackStorm’s slick UI, you can use it to create the rule. Or use CLI:
st2 rule create rules/diskspace_remediation.yaml
Create a large file (an action in our sample pack does this for you), and see how StackStorm fires the actions. If you create the large file somewhere else, check that you’ll get an incident in VictorOps. Now that you know it works, enjoy: this irritating “out-of-disk space” problems will be auto-fixed before the page would even reach you.
And one more key thing: Manage your automation as code. Create an automation pack – just as we did with st2_demos, commit to git, review, and deploy by st2 pack install. Or share it on github and exchange auto-remediation patterns and run books with your fellow devops – as code!
Hope this gives you a good start on the path to auto-remediation. At first, setting up StackStorm just for the sake of one simple integration may seem an overkill. But now that you have it all set up, adding automations is easy, almost addictive. Soon you’ll enjoy the compound value of rich action library, automation control plain under source control, and auto-remediations that keep your pager from going off at night.
And did you drink ChatOps cool-aid? Check what it can do for your operations, like these guys did, and stay tuned for our next blogs!