6/18/2019 by m4dcoder
Orquesta is the new workflow engine in StackStorm. If you are on the fence choosing which workflow services to use from AWS, Azure, or GCP and you are thinking that this post is too long to read, then just skip ahead and run StackStorm.

Orquesta is a new workflow engine that the StackStorm team has been passionately working on since its GA release back in StackStorm v3.0. The workflow engine is general purpose and supports a wide range of use cases such as business process automation, cloud orchestration, and life science data processing. Workflow definition is structured in YAML that is composed into a graph for the engine to conduct execution. You can take Orquesta for a spin when you install StackStorm today. But we are seeing a growing trend with Workflow as a Service to orchestrate cloud services and functions. In the spirit of experimentation and following up on running StackStorm actions serverless as AWS lambda functions (see /2017/12/14/stackstorm-exchange-goes-serverless/), we want to take Orquesta for a spin on the serverless framework (https://serverless.com).
Serverless functions have limitations when doing complex work. They are meant only for a single task that take input, spin, and return output. Solutions atop Function as a Service (FaaS) will perform sophisticated work and require coordination, state management, and data sharing. Workflow is one of many ways to handle the coordination and state. It is easy to grasp the concept of workflow for a large category of tasks. This lets users focus on the logical part of the solution and not on the plumbing. Cloud providers see this gap.
Today, each of the major cloud providers offers their own workflow service to stitch these functional units together. There are AWS Step Functions, Azure Logic Apps, and Google Cloud Composer. However, each workflow service is based on a different concept, with different workflow definition languages, and varying contents and connectors for integration. AWS Step Functions is based on the concept of a state machine. Google Cloud Composer is based on directed acyclic graph and requires user to program the workflow in python. Azure Logic Apps define workflows in JSON and the logical flow of tasks are reversed where a task only runs on a trigger or after one or more required tasks complete. Over time, as users put resources and investment into developing these workflows, we believe they will find it expensive and difficult, if not impossible, to migrate from one provider to another.
On the other hand, StackStorm is open source and integrates with multiple clouds. In our experiment, we want existing users to keep building on their existing knowledge. If they are already developing Orquesta workflows in StackStorm, moving to the Orquesta serverless workflow solution should be immediately familiar. An Orquesta workflow is defined in YAML and is made up of one or more tasks. Each task specifies what action to execute, with what input, which set of tasks to execute next when the task completes, and what to output. The following is an example Orquesta workflow definition. In this mock up, the workflow starts with the `init` task that branches for the `create` task and the `check` task. In this example, the `create` task waits a few seconds before creating a file which the other branch expects. The `check` task checks if the expected file is created and if not perform some other work before checking on the file again. This use case is one of many that ranges from a simple sequential workflow, to workflow with parallel branching and join, and to ones with complex logic and remediation.
version: 1.0
description: >
A sample workflow that demonstrates how to handle rollback and retry on error. In this example,
the workflow will loop until the file /tmp/done exists. A parallel task will wait for some time
before creating the file. When completed, /tmp/done will be deleted.
vars:
- file: /tmp/<% str(random(1000000, 9999999)) %>
tasks:
init:
action: core.local cmd="rm -rf <% ctx().file %>"
next:
- when: <% succeeded() %>
do: check, create
check:
action: core.local
input:
cmd: >
echo 'Do something useful here.';
if [ ! -e <% ctx().file %> ]; then exit 1; fi
next:
- when: <% succeeded() %>
do: delete
- when: <% failed() %>
do: rollback
rollback:
action: core.local
input:
cmd: >
echo 'Rollback something here.';
sleep 1;
next:
- when: <% succeeded() %>
do: check
create:
action: core.local cmd="sleep 3; touch <% ctx().file %>"
delete:
action: core.local cmd="rm -f <% ctx().file %>"
Before we describe our serverless application, we have to first understand how the workflow conductor functions. We are using the same Orquesta workflow conductor that the core StackStorm platform uses. The workflow conductor is designed to be able to run asynchronously, to serialize the workflow execution state, and then deserialize the data to continue where the workflow execution left off. The workflow execution state contains all the information needed to continue the workflow execution. It contains a copy of the workflow definition, the workflow input, sequence of tasks that have been executed, and the changes in context as tasks progress.
Our serverless application (architecture diagram below) is deployed to AWS and consists of two handlers or lambda functions: an API handler and a workflow handler. The API handler is triggered by POST requests from the API gateway. The body of the POST requests contains generic request to either save the workflow definition or create an entry for the workflow execution in the database. On receiving a POST request, the API handler processes the request and write the data into the WorkflowDefinition and WorkflowExecution tables in DynamoDB appropriately. To facilitate the API calls, we have a simple CLI command that saves the workflow definition from a local YAML file and another command that request workflow execution given the ID for the saved workflow definition.
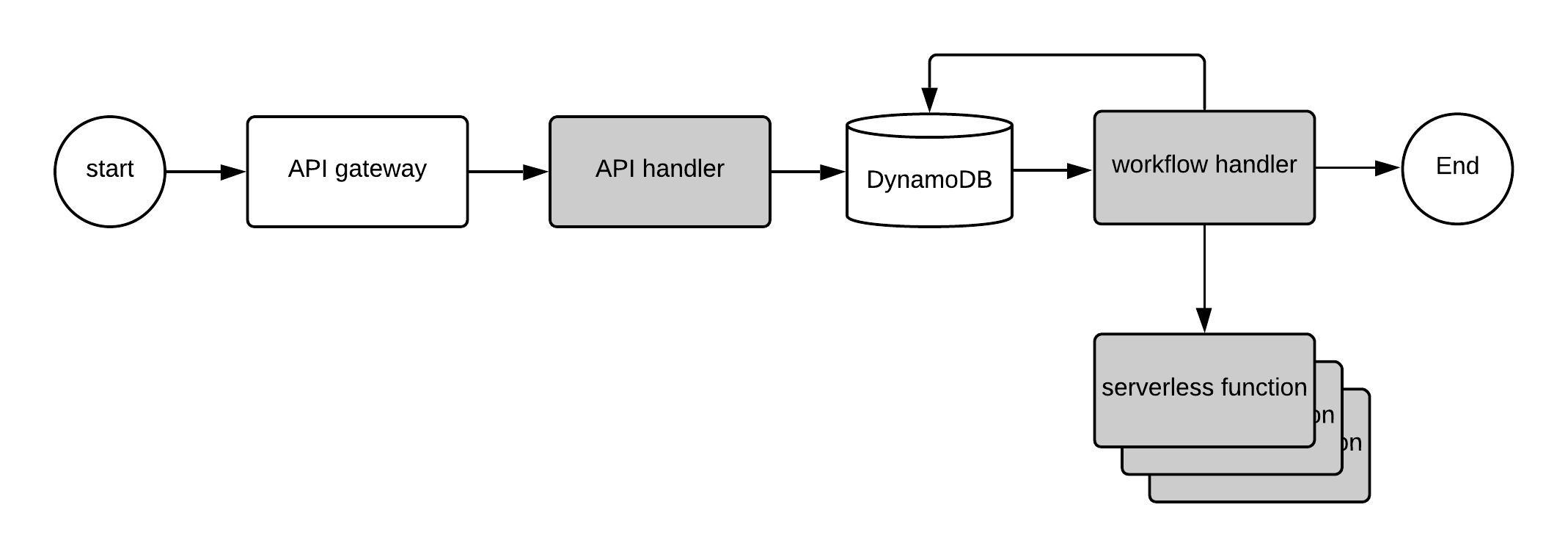
The workflow handler is triggered on insert and update into the WorkflowExecution table. On insert, the workflow handler initializes the Orquesta conductor with the workflow definition. The conductor inspects the workflow definition to validate and ensure correctness. Then the workflow handler requests the conductor for the initial set of tasks for execution. For each task, the workflow handler invokes the defined action. The action that is supported for the task in the workflow definition is just API call over HTTP. Referencing back to our blog on running StackStorm actions as AWS lambda functions, we can see that as this prototype is built out, we can reuse and call any actions that are in StackStorm Exchange across multiple cloud providers.
Back to the workflow handler, the action executions are synchronous in this current iteration of the prototype. On completion of the action executions, the workflow handler updates the conductor. Since the workflow handler only has a limited time to execute, 900 seconds for AWS function timeout, it does not continue executing the next set of tasks. Instead, the workflow handler serializes the conductor internal state and updates the record in the WorkflowExecution table. This table update triggers a separate call to the workflow handler that rehydrates the Orquesta conductor to run the next set of tasks. This cycle continues until there are no more tasks to execute in the workflow definition.
Let’s look at the cost of running our prototype on AWS. For each workflow execution, we are making 1 API handler invocation and 2N + 4 workflow handler invocations where N is the number of tasks. The 2N is a result of update of the task state which triggers workflow handler invocations due to the table updates. The extra 4 workflow handler invocations per workflow are due to trigger from the initial write from the API handler and subsequent workflow state updates from requested, running, to completed. In addition, there are a total of 2N + 2 DB reads and 2N + 4 DB writes. Given a sequential workflow with 10 steps and we are executing 1 task per seconds for 30 days. This equates roughly to 2.6M tasks (or 260K workflow executions). In the current iteration of the prototype without any optimization, the cost roughly $30 is estimated to be half the cost of running a similar workflow in AWS Step Functions at $64. Depending on the volume of work, the cost difference here is inconsequential. The true cost is the ability to leverage existing knowledge and reuse workflows and codes across traditional infrastructure and multiple clouds. Having the option to deploy code on more than one cloud providers keeps competition healthy.
Cloud services and functions may have freed up developers’ time on infrastructure availability and scalability, and deployment with the lure of a lower cost of ownership. But any application with reasonable complexity involving multiple steps is not trivial to put together with the constraint on processing, moving data, and managing state. Competition is healthy and cloud providers are differentiating by offering specialized services such as analytics and machine learning. User is likely going to use more than one services to solve complex problems. If not already, the new normal is interaction with multiple cloud providers, private and public, consuming specific services from any cloud providers that can best meet their application requirements and company policies. Thus, there is a need to orchestrate these disparate services and functions to achieve the ultimate goal. We strongly believe users are better off with a neutral orquestador, pun intended, such as StackStorm, which can be deployed to any number of environments today, with freedom to orchestra across multiple providers, encourages user to build on existing knowledge, and empowers user to orchestrate no matter where they are in their cloud journey.