July 15, 2015
by Evan Powell
Insights from WebEx Spark’s talk at the OpenStack Summit on how they boosted operational agility
Recently I watched again the presentation Reinhardt Quelle from Cisco Spark/ WebEx gave at the OpenStack Vancouver summit. It is an engaging presentation that covers a number of patterns, and a few anti patterns – everything from how they shifted their culture and org structure to Riak vs. Cassandra and PaaS vs. IaaS and much more besides. StackStorm does get a positive mention, so I’m biased – but that’s just a small piece of what is a great talk.
In this blog I’ll give you the cliff notes and some pointers to dive into relevant sections.
If you find this interesting I strongly recommend that you invest 45 minutes to watch the original.
Also – Reinhardt’s team will be co-hosting the upcoming Event Driven Automation Meet-up in San Francisco at their offices July 29th. Stop by to meet the team and dig in with them on these and other subjects.
Culture:
Reinhardt starts off by providing some context, beginning with the approach Cisco took to setting up Spark. Leadership had already determined that trying to gradually evolve WebEx operations and development towards DevOps best practices was fraught with difficulty and likely to fail.
Instead of trying to evolve WebEx, leadership decided to set up Spark as a skunk works. The core team was hand-picked from multiple organizations within and outside of Cisco. They were then brought into a room and told “you are fired” from whatever you have been doing and asked to leave the room. They were then brought back into the room and told, “congratulations, you’ve been hired into this brand new company.”
Yes, it is a bit corny. But it seems to have worked as the approaches taken by Spark are much more similar to that of “born on the web” companies than those that I have seen at other large firms like Cisco.
The culture that was adopted as they started off with a clean slate included seeing operations fundamentally “as a software problem.” As Reinhardt goes on to say, “we don’t have a traditional operations team.”
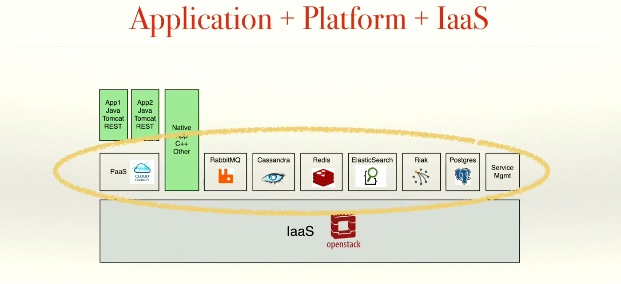
While they do not have silos (and, yes, developers do carry pagers), they do use the layers of their architecture to delineate responsibility. So for example there is a platform team – Reinhardt leads this team (the area within the yellow oval in the drawing), and there is an application team and a client team (those green boxes). And underneath there are IaaS layers largely from within Cisco and, as discussed below, from outside Cisco as well.
Multi data center and multi IaaS strategy and technologies:
Having discussed the culture and team background of Spark, Reinhardt dives into their current footprint. And that too gets pretty interesting pretty fast.
It turns out that while Reinhardt is an OpenStack power user and Cisco is a large operator of OpenStack clouds that the Spark platform that Reinhardt’s team is building and running operates across more or less any IaaS and certainly any OpenStack provider including internal private clouds and public clouds as well.
Spark runs in at least 5 data centers with 4 different providers of IaaS. They use replicated pairs of data centers as well to insure uptime and data retention and compliance.
And they have sensitivity to data locality, what they call at [14:05] the “Snowden effect.” For example, a data center provider in Germany that only has facilities in Germany is used to insure data locality for German customers.
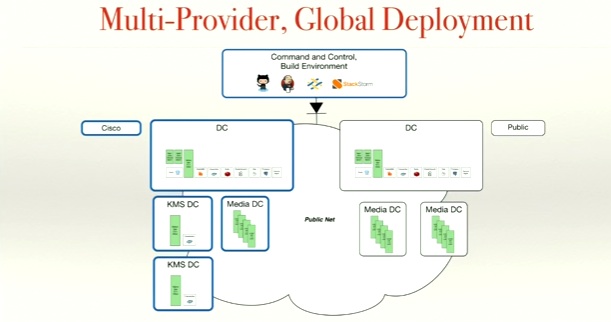
What is more, as you may have noticed from the first image above, they also have Cloud Foundry running. And even that they deploy and then operate across whatever IaaS meets their needs.
And then consider that some of their workloads are extremely latency sensitive – real time video and voice for example — necessitating lots of media bridges with their particular networking requirements spread around the world.
So how are they able to remain cloud agnostic?
As far as I can gather, it boils down to avoiding lock-in by designing to avoid it from the start so that all controls, service assurance, and processes are themselves not dependent on a particular provider whether internal or external.
As Reinhardt points out, everything sensitive is run centrally and then actions are pushed, as needed, into their cloud providers. For example their keys and their command and control systems are all centrally hosted.
Here Reinhardt points out that this approach – of centralizing control outside of each individual cloud and pushing actions down to the clouds – also is important from a security perspective. He mentions the unfortunate case of CodeSpaces which back in 2014 had their public cloud access hacked, where they had also stored all of their keys, resulting ultimately in such a horrible exploit that the company went out of business.
Another example of Reinhardt and team designing to avoid lock-in is their use of templates to define application dependencies and operations policies. They basically forked (my interpretation) Heat to do this – they do not use OpenStack Heat itself. Why? Again, because this allows them to abstract away from each flavor of OpenStack or other IaaS they utilize.
StackStorm fits this theme and design very well. StackStorm abstracts automations away from the underlying integrations and enables users to carry those automations across multiple environments – as code. Users start with specific scripts that you may already have – or they pick them up from the community (where you’ll find more or less all north and south bound calls to public and private clouds and virtualization from AWS through vSphere) – and then combine them via workflow into end to end automations. As Reinhardt mentions in his talk the first win is often just taking existing scripts – in their case they had done a lot of work with Fabric before StackStorm arrived – and making those callable via an API and even CLI. He calls StackStorm for this use case an “execution environment for their automation,” which is a nice way to summarize this capability.
It may be obvious, but by command and control Reinhardt also means all service assurance. So their monitoring, logging and so forth are all brought by them to every cloud and every data center, they do not use (with very few exceptions) such services provided by a particular cloud.
IaaS vs. PaaS and what about Containers (hello Docker!)
Yet another interesting subject is how Spark decides when to run which type of application in which environment, whether IaaS or PaaS specifically (see 22:15). Reinhardt also discusses when and how containers are being used.
For stateless apps, PaaS works pretty well.
For those with persistent data stores, not so much.
Some applications do not fit, such as media bridges.
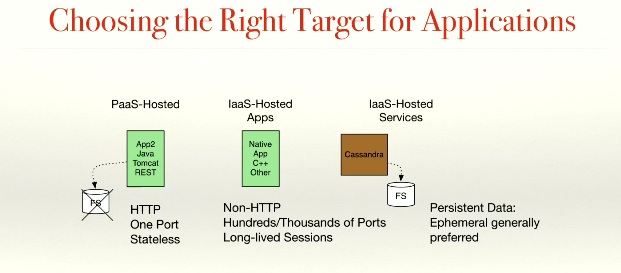
Of course, whenever possible application components are written in a “cloud native” manner, leveraging the 12 Factor App approach for example.
Interestingly enough, while Cloud Foundry is a fundamental part of their platform, they really see it as delivering approximately two of the 28 services that Reinhardt’s platform team needs to deliver. As such they have decided not to use Bosh or other CloudFoundry specific tooling since they want tooling to be generic across components.
That brings us to deployment where you get to see all the pieces dancing together (i.e. some event driven orchestration).
Deployment:
Not surprisingly given their design preference for consistency and abstraction away from specific implementation dependencies, Spark’s deployment processes are consistent whether the app components or services end up running in Docker or anything else such as Vagrant, CloudFoundry or other alternatives.
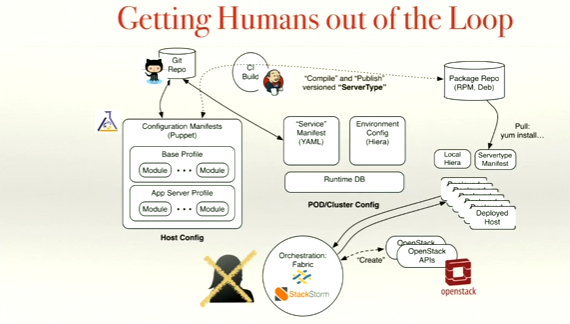
As the drawing indicates, the application calls the tune. Code check-ins of a certain type – for example media bridges – are treated throughout the process differently than others. Today they use Puppet’s Hiera for the central store of truth however they are actively moving to MongoDB in part due to their growing scale and ease of integration into StackStorm (although StackStorm supports both patterns).
While Reinhardt does not share metrics on how many deploys they are doing, my understanding is they can do many deploys per day per each of the 26-28 components if needed. That’s a huge boost in customer and competitor responsiveness from the sort of quarterly release train that many older operations still follow; by my math they have achieved by comparison a 60x boost given that there are roughly 60 work days in a quarter.
As the drawing suggests, StackStorm increasingly is playing the role of closing the loop as well as the automation integration and orchestration layer. We anticipate working with the team more on some of the use cases around auto remediation as this is becoming a primary use case for StackStorm in other larger operators.
Docker (I promised I’d mention Docker!) is specifically being used in their build environments and actually they plan to start deploying media bridges on Docker; once again that orchestration is delivered by StackStorm.
Summary
I didn’t even touch on the fascinating discussion about when workloads remain on premise vs. moving into the cloud, or about how they decide which data services to run (Cassandra v. Riak example) and how licensing factors into that decision, or any of the other many insights including their use of ChatOps. If any of the above piqued your interest I highly recommend you invest the 45 or so minutes needed to watch the presentation as well. I found it well worth the time.
Also, again, I’d like to invite you to join the Event Driven Automation Meet-up. We recently hosted a meet-up at Facebook to learn more about FBAR and related projects which enables Facebook to run their environment with apparently just a few people in operations. As mentioned above, the next meet-up will be hosted at Cisco in San Francisco on July 29th where Reinhardt and team will present; yes, we do expect that event to be WebEx’d or otherwise streamed.
Finally, I’d just like to say congratulations to Reinhardt and the entire Spark team. We enjoy working with them and learning from them. Their success shows that unicorn like agility and scalability can emerge within much more traditional enterprises. I’m sure it has not been easy. It is impressive as heck.