December 8, 2014
by Tomaz Muraus
StackStorm v0.6.0 was recently released. This release includes many new features, bug-fixes and improvements.
One of the new features this release brings is user content sandboxing and isolation. In this post we will share why we have done this, and what benefits this brings to our users. We’ll also take a quick technical dive and look at the implementation details.
WHAT IS CONTENT PACK SANDBOXING AND ISOLATION?
Users integrate StackStorm with 3rd party systems (AWS, OpenStack, Puppet, Git, JIRA, Libcloud, etc.) and extend its functionality by installing one of the official or user-contributed packs from the StackStorm Exchange.
A pack can contain three different types of content / resources:
So an operational pattern — something you want automated — consists of a sensor / trigger to tell you an event has occurred, followed by a rule to pick what (if anything) to do next, followed by an action — which can be a workflow — to actually do it.
In the previous versions of StackStorm, sensors and Python actions were executed inside the main sensor container Python runner process respectively. This means that all the actions and sensors had access to all the Python packages and libraries which were available to other StackStorm components.
Our goal is to make writing actions and sensors as simple as possible, which means that they can depend on other Python packages. There are multiple problems with running this user content inside the same process as the StackStorm service:
We solved those limitations by introducing sandboxing and isolation for sensors and Python actions.
As noted above, actions can be written in an arbitrary programming language, but since our platform is written in Python, actions written in Python are first-class citizen and receive some additional benefits such as dependency management, sandboxing and isolations and more.
Sandboxing is handled by using Python virtual environments. Upon pack installation, we create a new virtual environment for this pack and also install all the Python dependencies declared in the requirements.txt into this newly created virtual environment.
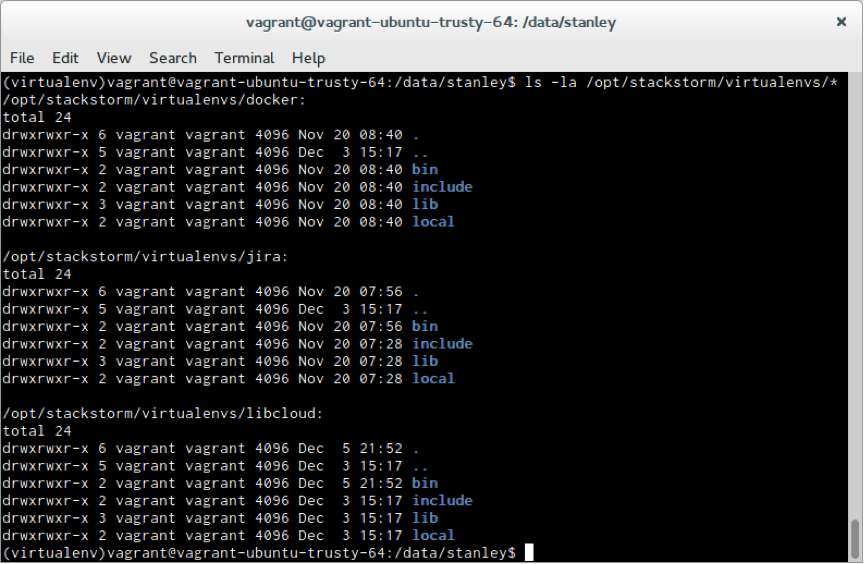
Each pack now has it’s own virtual environment.
The isolation is handled by executing sensors and Python actions inside a new process which uses previously created virtual environment which is specific for this pack.
For more information on implementation details, please see the section below.
BENEFITS
This feature provides many benefits to the end user (and also to the system as a whole).
Less work for the end user
Python dependencies are now automatically installed during the pack installation, which means the user no longer needs to deal with installing the dependencies manually.
No more dependency hell
Different packs can now depend on a different version of a particular Python library. On top of that, pack dependencies and code no longer interfere with other StackStorm dependencies.
Easier testing and debugging
Previously, if user wanted to test an action or a sensor, they would need to run the whole StackStorm stack or at minimum sensor container, action runner and the API service.
With this new approach, we now have a wrapper script which is ran inside the subprocess and used to run the sensor or action code. This means that if a user wants to test an action or a sensor in the context of StackStorm, they can simply run the wrapper script with the correct arguments. On top of that, this also makes automated testing easier — something we think is fundamental.
Other common sandboxing and isolation benefits
Code running in a separate process means that we now have more control over code that is misbehaving.
If the user code is misbehaving, we can simply kill the whole process to prevent the code fromaffecting StackStorm components or other sensors / actions.
Process level isolation also has some limited security benefits (user code can no longer directly manipulate the service code and state, etc.), but those benefits are secondary because securely sandboxing and running user provided code is a lot more complex and a whole different story.
IMPLEMENTATION DETAILS
In the Python world, the de facto tool for creating isolated environments is virtualenv, so we have decided to go with that.
In a nutshell, virtualenv works by creating a new directory for a virtual environment and copying python binary to this directory. On top of that, it also copies and creates other necessary files and directories such as site-packages there.
Python binary is designed to search for packages and modules in directories which are relative to the binary’s path. This means that when you use python binary from virtualenv, it will use packages which have been installed into this virtualenv.
If you want to know more, I recommend that you watch this talk titled “Reverse-engineering Ian Bicking’s brain: inside pip and virtualenv” from PyCon 2011.
In StackStorm’s case, we create a new virtual environment for a pack and install all the pack dependencies when a user installs a pack using packs.install action. If for some reason you want to manually create a virtualenv (e.g. you didn’t install a pack using packs.install action) or update pack dependencies, you can do that by running packs.setup_virtualenv action.
Underneath, packs.setup_virtualenv action creates a new virtual environment (if one doesn’t exist yet) and installs pack dependencies that are specified by the pack author in the requirements.txt file in the root directory of a pack.
Now that we have an isolated Python environment for our pack, we need to use it when running our sensors and Python actions. That’s where the fun and tricky part beings.
Using the multiprocessing module from stdlib is out of the question since processes spawned using multiprocessing use the same Python binary as the current / parent process. This means we can’t use our isolated environment, and given the way multiprocessing works, we also need to pass a callable which is to be run to the constructor. This won’t work in our case because the user code we want to run is stored in a separate file. In theory we could get it to work by doing some importlib, eval and sys.path hackery, but this is very hacky and we still have the virtualenv problem.
This leaves us with pretty much only one option – spawning a child process using the subprocess module from stdlib. This module allows you to spawn a new child process and connect to its input/output/error pipes, and obtain its return code.
To get this to work, we need a wrapper script which will be executed by a virtualenv python binary in a subprocess. This wrapper script is responsible for running the user content (sensor or a Python action) using the correct configuration.
You can find the source code of a sensor wrapper and python action wrapper here – sensor_wrapper.py, python_action_wrapper.py.
The subprocess module allows you to establish bi-directional communication with a child process using pipes, but we have decided to not use this functionality. Instead of passing all the required arguments to the wrapper using the child process’s stdin, we pass all the arguments to the child process via command line arguments.
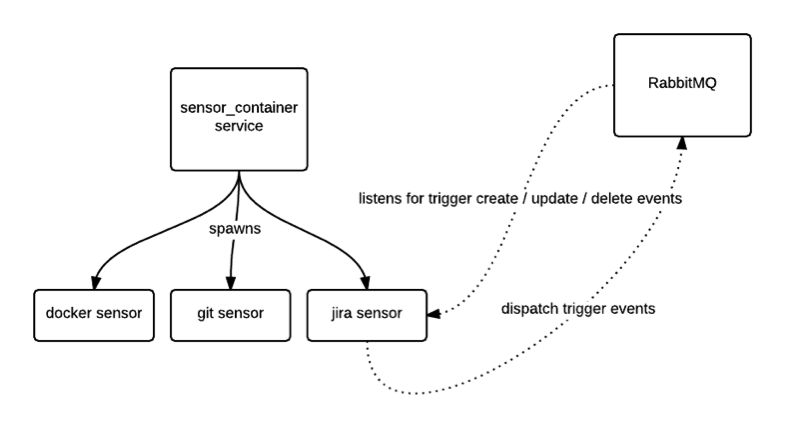
And in the case of sensors, when an event is detected, the child process publishes a message directly to the event bus (RabbitMQ) instead of passing this result to the parent and letting the parent do the dispatching.
Some of you might say that establishing a connection to the message bus in every sensor process is wasteful and introduces a lot of overhead. In general, this is true and you should always try to reduce the number of open connections and / or use some kind of multiplexing / connecting pooling mechanism, but in this case it’s actually not a big problem.
First of all, sensors are long running processes so those connections are long lived. Secondly, RabbitMQ is written in Erlang, and Erlang processes are light-weight with a small memory footprint, so the actual per-connection overhead is pretty small.
This makes the whole thing more self-sustaining and easier to test, debug and scale. If a user wants to test or debug a sensor or an action in the StackStorm context, they can do that by directly invoking a wrapper script with the correct arguments.
Now that we have a wrapper script, we simply need to execute it using the Python binary that is specific to the pack from which the sensor or action is coming from — you can find a source code for that here.
We also allow users to run StackStorm components inside a virtualenv itself (inception!) which means there are some more edge cases we need to handle. If a user is running StackStorm components inside a virtualenv, we detect that and add site-packages from that virtual environment to the PYTHONPATH for our child process (see this piece of code).
On top of allowing us to avoid dependency hell and other user benefits mentioned above, this also has other benefits for us. The wrapper script is more or less self-sustaining, which means it’s now easier to run sensors and Python actions on different servers, making it easier to scale.
And yes, using a process per sensor and action does induce some overhead (notably memory usage), but this overhead is negligible, and the scaling and other benefits are more than worth it.
CONCLUSION
To recap, this new feature allows users to avoid dependency hell, and makes sensors and Python actions easier to test and debug. Additionally, it removes the burden from the users since the pack dependencies are now managed and installed automatically.
We encourage you to give StackStorm v0.6.0 a go and see the benefits yourself.
As always, if you need help or have any questions or feedback, you can reach us at #stackstorm on irc.freenode.net or via email at moc.mrotskcatsnull@troppus.