December 1, 2014
by Patrick Hoolboom
I’ve spoken at a couple of events, and chatted with hundreds of people at these events about an idea that has been swirling around in my head for a while now. This idea has gnawed at my subconscious throughout a big part of my career in IT Operations, but I was never really able to put my finger on what was bothering me. I just knew that lack of visibility and consistency in procedures drove me crazy. The opaque nature of action performed during an outage, or even a scheduled operation was frustrating. Post mortems were a nightmare of hazy memories, chat transcripts, and various permutations of ad hoc log parsing.
As I sat late one night, back in May, whiteboarding some ideas with my boss, it finally materialized. I explained to him how I felt that Operations teams need to identify behaviour patterns much like how developers have software development patterns. He started quickly jotting down some things on the board and we ended up with what, at StackStorm, we refer to as Operations Design Patterns.
Operations Design Patterns
The general idea in the beginning was that in the IT Operations/Infrastructure world, most of the behaviors or procedures can be distilled down to the essentials bits. We can then take those bits and templatize them. In theory, we should then be able to compare these templates…and even share these templates.
Most groups already have these templates. They keep them in wikis, or runbooks. Maybe even in scripts. None of these give us the combination of abstraction, visibility, and flexibility that we need. People forget to update wikis. Runbooks can be too heavily tied to the technical underpinnings of the tasks, and scripts are actually the worst. They are the easiest for us to write, but the hardest for us to maintain. They are completely opaque from the outside, and most languages give us too many ways to do any single task. This is fantastic for development, but can make modeling procedural patterns all but impossible.
The point I want to make is that most organizations are already aware of these patterns on some level and tracking them in some way. The shift we need to make is to focus less on the steps in the pattern, and more on the patterns themselves. If we make the patterns the first class citizens, it completely changes how we think about our procedures. The storing, reviewing, and improving of these templates will be a core piece of how the team operates. This starts to get a bit utopian, I know. There are definitely technical requirements, as well as team buy in, and consistency for this to really work.
The Basic Pattern: Workflow vs Action
One of the most basic patterns that I’ve come to see everywhere is the idea of separating the procedure (or workflow) from the actions that are being performed. We need to take the logic from our procedure and extract it out, away from the actual actions being performed. For example, we can build a workflow out of a basic remediation procedure.
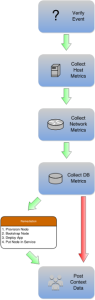
An event happens, that starts us down the path of troubleshooting this problem. We know we need to collect a certain amount of diagnostic data, then choose the appropriate remediation tasks based off of this data. At the end, we communicate what was done and the current state. We could build these kind of diagrams around dozens, if not hundreds of different kinds of troubleshooting scenarios. The specifics of the underlying task are unimportant in the context of modeling the procedure, what really matters is the pattern.
We now can identify these patterns but we don’t yet have a clear, standardized way to express them. One of the key pieces of this model is finding this language. It must come via a workflow engine or other means that makes the workflows themselves executable. This is vital, otherwise our workflows are only slightly better than the wikis they replace. When we find a language to express our workflows that is not only executable but also human readable, we essentially end up with living documentation. The very documents we use to record our procedures are what we run to follow those procedures.
The Atomic Action
Another basic piece to this is the concept of atomic actions. To quote Doug McIlroy:
“This is the Unix philosophy: Write programs that do one thing and do it well. Write programs to work together.”
In a perfect world there would be virtually no logic in the scripts that perform the actions. The logic should be expressed in the higher level workflow language. For ease of readability, and quick manipulations you do not want logic that impacts the decision tree of the procedure buried in the code. The reality is that it is probably not practical to abstract out all of the logic, and we will end up somewhere in between pure scripts, and pure workflow when it comes to where the logic lives.
Lego blocks are a great analogy.
Having large amounts of logic in the scripts is like using highly specialized Lego bricks. Like this one:

It would do one job really well, and we could get it up and running very quickly. The problem is that we can’t easily make changes that don’t fit within the design constraints of this Lego fence. We end up hacking pieces around our fence just to get the full functionality we need.
The other option, more akin to using atomic actions and workflow, is to build everything out of the smallest brick possible.

This gives us the most power and the greatest flexibility but also takes the most time. We could build giant structures out of these, and down the road if we needed to, switching one of them to red, is as easy as replacing that single brick.
The Reality of My Utopian Ops Dream
This is my first stab at writing this idea down and I know there are going to be holes in it. Places where this just doesn’t fit. Mostly due to time constraints, or lack of the necessary technology. The two big problems I see are:
My thoughts so far are that we can attack the first point by rallying a community around this idea. If we collaborate and share our ops patterns we will greatly reduce the ramp up time necessary to get a model like this working. Not only that, but we could start to standardize practices across organizations from the get go.
I don’t want to dig into the specific technologies that are out there at this point but at StackStorm we are using Mistral as the main workflow engine. Mistral combined with the “everything as code” nature of the StackStorm product has helped us overcome a lot of the technical roadblocks in adopting the Operations Design Patterns concept.
This has been a fairly rough brain dump of my thoughts around how to improve IT Ops via capturing Operations Design Patterns. I’m hoping as I get this discussion going more it will continue to grow and improve. I would love to hear feedback from people on this. Feel free to contact me on Twitter, or on IRC: DoriftoShoes, generally found in #stackstorm on Freenode.