September 23, 2015
by Lakshmi Kannan
If “SLAs”, “five 9 uptime”, “pager fatigue” and “customer support” are phrases you use everyday in your work, you know by now auto-remediation is a serious use case. If you are running critical infrastructure of any kind, you may already be looking into auto-remediation, or even using it like Facebook, LinkedIn, Netflix (more on that later). The idea is that if you are running critical systems of any kind, you need to see when events happen and to act on them as fast as humanly possible. Actually, no, to improve mean time to recovery you need to respond FASTER than humanly possible.
If I start to sound like “automate everything”, that’s because I am saying that in less direct terms. As a developer and an operations person, I enjoy automation as much as anyone. StackStorm is the machine you want! I wish a system like StackStorm existed in my previous gigs so I could have just focused more on automating than worrying about inventing a platform to perform the automation. I also wish I had slept more than being woken up by the sound of pagers and phones telling me about a problem that could have been remediated by a piece of code!
This post – and this automation – is inspired by one of our largest users of StackStorm for Cassandra auto-remediation – Netflix. They are speaking about how they manage Cassandra at the Cassandra Summit so you can learn more about their overall approach there and can spend quality time with them in an upcoming meet-up as well at their HQ.
In this blog post, I’ll walk you through a really common problem – a bad host in a Cassandra cluster – and how you can leverage StackStorm to auto-remediate it. I have been a long time happy Cassandra user and I definitely enjoy the solid performance it provides applications. We also use it at StackStorm in our yet to be released Analytics platform. StackStorm would complement Cassandra so well by handling the operations.
A common problem is a host in the Cassandra ring dies and now you are running in low availability mode. Though Cassandra can deal with one node outages (depending on how you setup the cluster), you’d ideally want to replace the dead host with a new host asap. Typically, a monitoring system watches the cluster for dead nodes (nodetool status) and sends an event upstream. An alerting system then figures out if the alert needs to be a page. If so, a system like Pager Duty is then used to wake up a poor soul. I say “wake up” with confidence because I honestly can’t remember a failure that happened during regular business hours. Maybe the computers feel lonely post work hours but I digress ;). A DevOps engineer then validates that the alert is indeed positive, figures out a replacement node, spins a VM, deploys Cassandra on the box (depending on whether you use Chef or Puppet or StackStorm you have Cassandra deployed automatically) and then invokes a set of procedures to replace the node. Let’s walk through the actual steps involved in replacing a node. The steps are listed in this runbook from our friends at Datastax. As you can see, it’s a 6 step process and it involves an engineer monitoring the system carefully to make sure things are going according to plan. This pretty much steals a few hours from an engineer’s time which could be spent on something more productive.
StackStorm has got your back! In the StackStorm world, the node down event from the monitoring system goes to StackStorm, StackStorm then acts on the event i.e. spins up a new VM with Cassandra deployed and replaces the dead host with the new host following the runbook codified as a workflow (Infrastructure as code!). If StackStorm fails by any chance, it then relays the alert to a human who can decide what to do. The power of such a tool will save you so much pain and effort.
Yes, you can see the code. We support infrastructure as code 100%. However – you can also see the automation via our brand new FLOW.

Here’s that code (actually YAML – and this syntax is emerging as a defacto standard – another discussion for another time):
version: '2.0'
cassandra.replace_host:
description: A basic workflow that replaces a dead cassandra node with a spare.
type: direct
input:
- dead_node
- replacement_node
- healthy_node
output:
just_output_the_whole_worfklow_context: "<% $ %>"
tasks:
is_seed_node:
action: cassandra.is_seed_node
input:
hosts: "<% $.healthy_node %>"
node_id: "<% $.dead_node %>"
publish:
seed_node: "<% $.is_seed_node.get($.healthy_node).stdout %>"
on-success:
- abort_replace: "<% $.seed_node = 'True' %>"
- create_vm: "<% $.seed_node = 'False' %>"
- error_seed_node_determination: "<% not $.seed_node in list(False, True) %>"
on-error:
- error_seed_node_determination
abort_replace:
action: slack.post_message
input:
channel: "#dsedemo"
message: "```[CASS-REPLACE-HOST] [<% $.dead_node %>] STATUS: FAILED REASON: SEED NODE DEAD. NOT HANDLED. ABORTED.```"
on-complete:
- fail
error_seed_node_determination:
action: slack.post_message
input:
channel: "#dsedemo"
message: "```[CASS-REPLACE-HOST] [<% $.dead_node %>] STATUS: FAILED READON: SEED NODE DETERMINATION FAILED.```"
on-complete:
- fail
create_vm:
action: core.local # You can call your create_vm workflow here!
input:
cmd: "echo Replacing <% $.dead_node%> with <% $.replacement_node %>"
on-success:
- stop_cassandra_service
on-error:
- notify_create_vm_failed
notify_create_vm_failed:
action: slack.post_message
input:
channel: "#dsedemo"
message: "```[CASS-REPLACE-HOST] STATUS: FAILED REASON: create_vm_with_role failed.```"
on-complete:
- fail
stop_cassandra_service:
action: cassandra.stop_dse
input:
hosts: "<% $.replacement_node %>"
on-success:
- remove_cass_data
remove_cass_data:
action: cassandra.clear_cass_data
input:
data_dir: "/var/lib/cassandra"
hosts: "<% $.replacement_node %>"
on-success:
- remove_replace_address_jvm_opt_if_exists
remove_replace_address_jvm_opt_if_exists:
action: cassandra.remove_replace_address_env_file
input:
hosts: "<% $.replacement_node %>"
on-success:
- set_jvm_opts_with_replace_address
set_jvm_opts_with_replace_address:
action: cassandra.append_replace_address_env_file
input:
dead_node: <% $.dead_node %>
hosts: <% $.replacement_node %>
on-success:
- start_cassandra_service
start_cassandra_service:
action: cassandra.start_dse
input:
hosts: "<% $.replacement_node %>"
on-success:
- notify_replace_host_started
notify_replace_host_started:
action: slack.post_message
input:
channel: "#dsedemo"
message: "```[CASS-REPLACE-HOST] [<% $.dead_node %>] STATUS: STARTED```"
on-success:
- wait_for_read_ports_to_open
on-error:
- wait_for_read_ports_to_open
wait_for_read_ports_to_open:
action: cassandra.wait_for_port_open
input:
check_port: 9042
server: "<% $.replacement_node %>"
hosts: "<% $.replacement_node %>"
timeout: 1800
on-success:
- remove_replace_address_env_file
on-error:
- notify_replace_host_failed
remove_replace_address_env_file:
action: cassandra.remove_replace_address_env_file
input:
hosts: "<% $.replacement_node %>"
on-success:
- notify_replace_host_success
notify_replace_host_success:
action: slack.post_message
input:
channel: "#dsedemo"
message: "```[CASS-REPLACE-HOST] [<% $.dead_node %>] STATUS: SUCCEEDED```"
notify_replace_host_failed:
action: slack.post_message
input:
channel: "#dsedemo"
message: "```[CASS-REPLACE-HOST] [<% $.dead_node %>] STATUS: FAILED```. REASON: BOOTSTRAP TIMED OUT."
We picked a simple case where a dead node is first checked to see if it is a seed node. Seed nodes are special in Cassandra and for the purpose of simplicity, we do not handle seed node replacements. Instead, as you can see, we abort the workflow if a node is a seed node. If it is not, then we follow the steps listed in the runbook one at a time. Each step in the runbook is codified as simple actions in StackStorm and placed in appropriate packs. For a brief intro to packs, read our documentation and check out the community packs available. All the actions listed in the mistral workflow are part of Cassandra pack
As you might guess, some of the actions need to happen on remote boxes. To be precise, they need to happen on the new box being spun up. It goes without saying, StackStorm needs passwordless SSH access (via keys) to this new box. You might also notice the notify tasks in the workflow. They post notifications on a specified channel in slack. This gives you visibility into the status of the workflow as it’s being run! The point here is instead of having to have a task that notifies at each task completion, you can configure the whole workflow to notify Slack. This is one of many ways we’ve made ChatOps a first class citizen, but I digress. There is a great blog about simplifying and extending ChatOps with StackStorm here.
StackStorm ships with a CLI and a lovely UI in the community version. The Cassandra pack comes with a nodetool action that you can use to run nodetool actions on cluster. For example:
st2 run cassandra.nodetool hosts=10.0.2.247 command='status'
You can also kickoff the replace host workflow manually using the CLI.
st2 run cassandra.replace_host \
dead_node='10.0.2.246' \
healthy_node='10.0.2.247' \
replacement_node='st2-dse-demo-replacement001' -a
Here’s a juicy screenshot of using the UI to run the nodetool action.
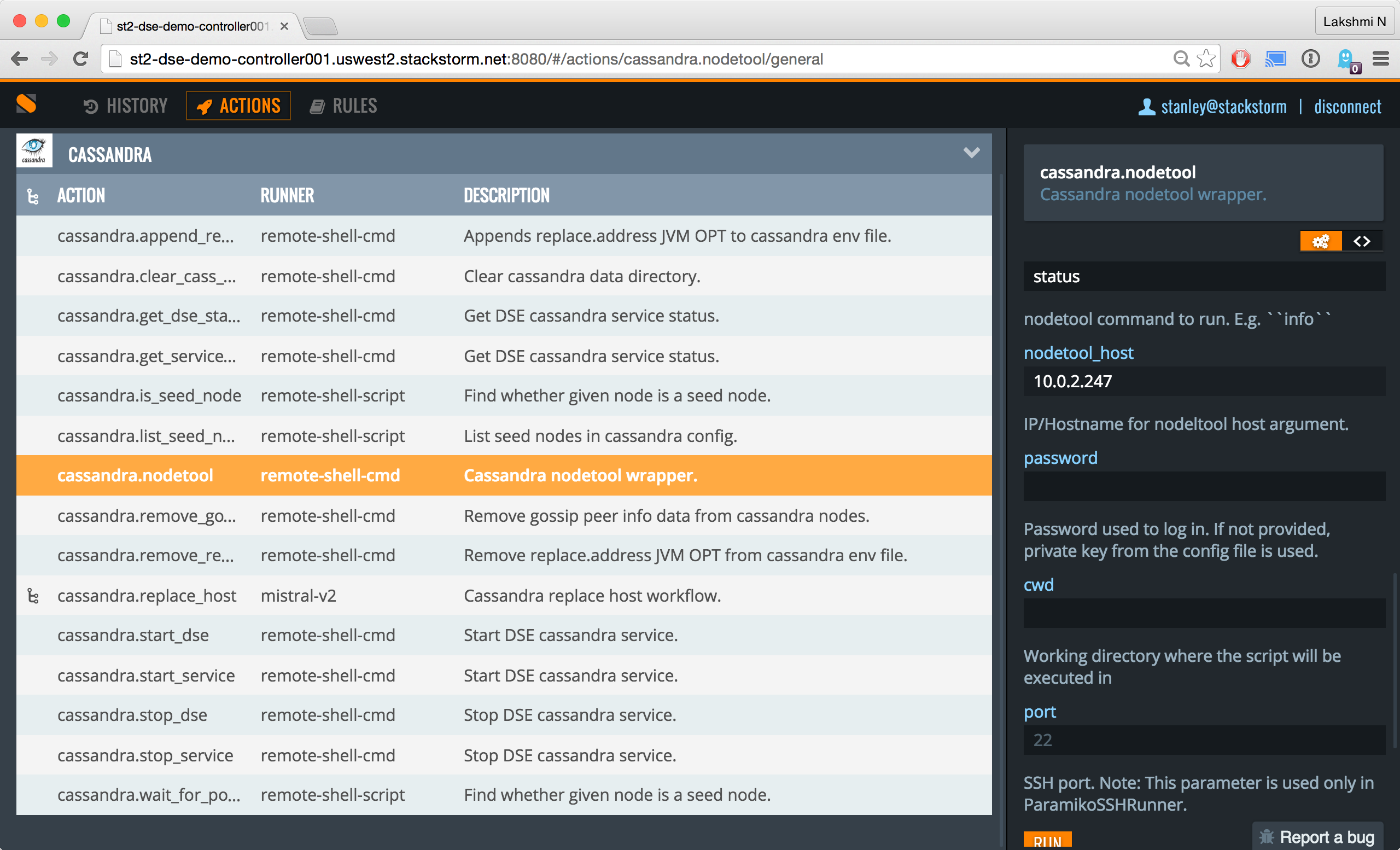
StackStorm has a concept of rules. Rules connect triggers (external events) to actions or workflows registered with StackStorm. Triggers can simply be webhooks. For active polling of an external system and other use cases, you might want to look at sensors. You could setup your external monitoring system like
sensu or new relic to post a webhook to StackStorm. Webhooks are registered by registering a rule.
See the sample rule definition below.
---
name: "replace_dead_host"
pack: "cassandra"
description: "Rule to handle cassnadra node down event."
enabled: true
trigger:
type: "core.st2.webhook"
parameters:
url: "cassandra/events"
criteria:
trigger.body.event_type:
type: "iequals"
pattern: "cass_node_down"
action:
ref: "cassandra.replace_host"
parameters:
dead_node: "{{trigger.body.node_ip}}"
healthy_node: “10.0.2.247” # usually you’d get this from consul or etcd.
replacement_node: "st2-dse-demo-replacement001" # usually you’d get this from consul or etcd.
See how we dropped straight to the code there? Pretty cool, huh. Of course you can do the same thing via the UI that actually spells out the IF and THEN relationship in rules page.
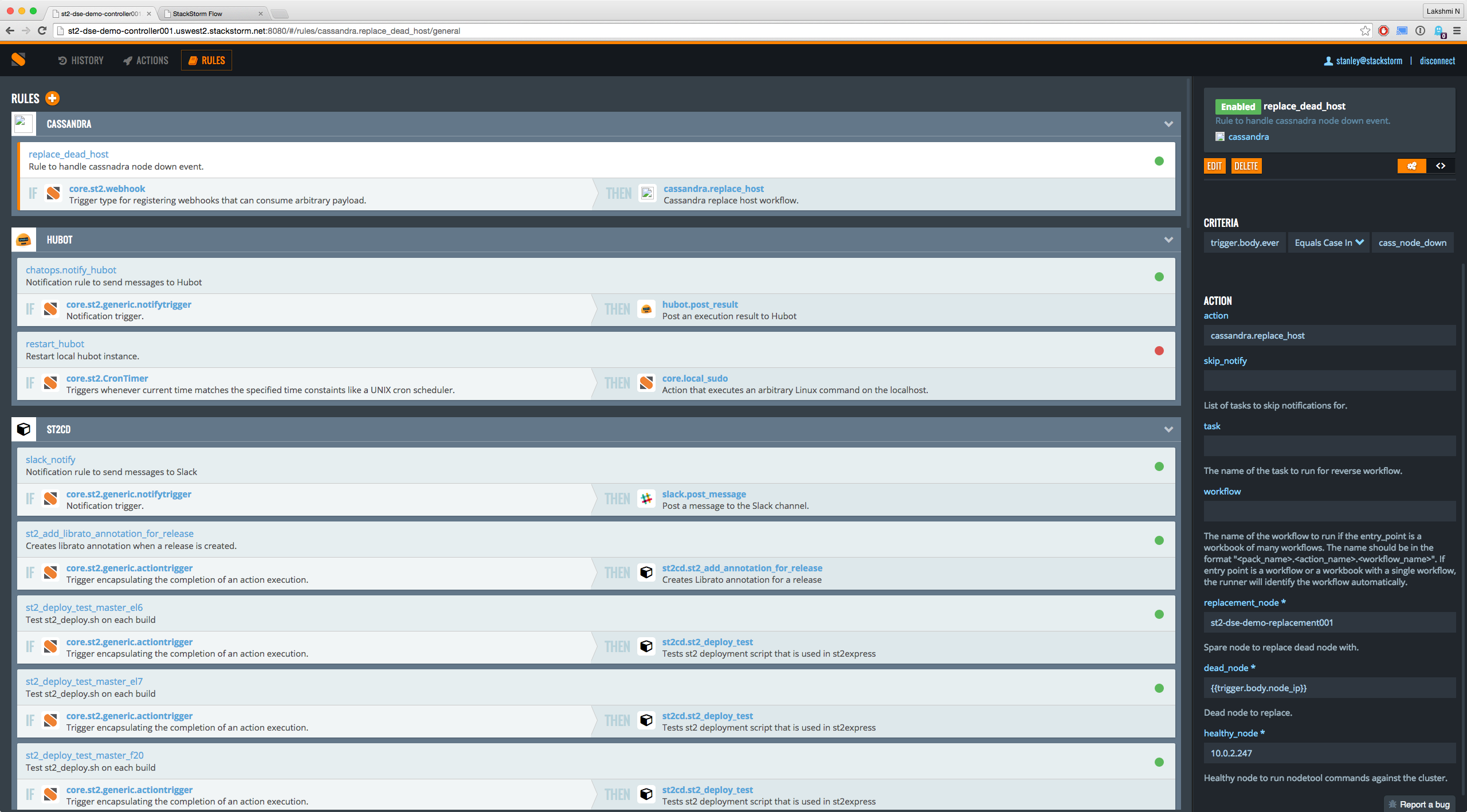
The webhook complete URL is https://stackstorm_host.com/v1/webhooks/cassandra/events. Whenever a webhook is received, the rule engine in StackStorm validates if the event_type is cass_node_down. If yes, then it invokes the replace host workflow with the dead node’s IP address (obtained from webhook payload) and a replacement node. An example webhook that you post to the URL will look like
{
"event_type": "cass_node_down",
"node_ip": "10.0.2.247"
}
In the real world, you probably have spares available with Cassandra pre-installed. If so, then you might include an action to get a replacement from set of replacements (perhaps via a consul integration) and use that in the workflow. If you want to spin a node as part of the workflow, you can do so as shown in the workflow. This will be slower as expected. So now you have things wired up and good to go!
If you think this is interesting, imagine remediations for all the important pieces of your environment that can benefit from a few steps being run in response to any action. Take a look at the StackStorm community for example – specifically the many packs now appearing here, and you can see for example hooks to security systems emerging. See where I’m going with that? There is a huge push now by some incredibly harassed companies and agencies to automate much more of their remediations – this time in response to security events such as unfriendly hackers.
We’re glad to hear that. Take a look at StackStorm and maybe ask some questions on the StackStorm community. Use our free trial of the enterprise edition or our all in one installer to get started.
We do support StackStorm – including the Enterprise Edition features – 24×7 in some mission critical environments. And we also are keen to get more and more users sharing their remediations as code. So jump in, the water’s perfect.
Sure, can! Check out our slack community where stormers and larger StackStorm community hang out and help each other! Feel free to register. You can also look at interesting contributions like packs, bug fixes and even new features! Perhaps you could also be motivated to open a pull request! We are also on
IRC or email us at moc.mrotskcatsnull@troppus. Feel free to subscribe to our newsletter to get interesting updates on StackStorm!